
Kaum drei Tage online, schon kriege ich ungebetenen Besuch — es ist ein bisschen wie bei Oggy und den Kakerlaken. In diesem Fall ist der »Gast« ein Crawler aus der Ukraine, den ich — bevor er es sich richtig gemütlich machen konnte — auch schon wieder vor die Tür gesetzt habe.
Losgeschickt hat das Biest, das in meiner Statistik personalisierte Backlinks wie 79.semalt.com/crawler.php?u=https://krikkit.uber.space hinterlässt, die Firma Semalt, die nach eigenen Angaben ein SEO-Tool für Seitenbetreiber*innen anbietet (Pardon, aber einen Backlink will ich Euch nicht auch noch spendieren):
Ich möchte gar nicht wissen, wie viele Neugierige auf diesen Crawler schon reingefallen sind. Der nämlich scheint leider nicht ganz so harmlos zu sein wie die Firma aus Kiew vorgibt. Vom Referrer-Spam mal ganz abgesehen, scheint der Semalt-Crawler auch fleißig Daten zu sammeln, Nutzer auszuspähen und gegen geltendes Recht zu verstoßen, wie Joram van den Boezem herausgefunden hat. Er vermutet hinter Semalt ein Botnet, das vor allem über Rechner in der Dritten Welt und in Schwellenländern läuft — wie The New Frontier (inzwischen offline) schreibt, scheint sich ein Großteil der Aktivitäten in Brasilien zu bündeln. Weiter heißt es dort:
Rewrite für den Semalt-Crawler: »It’s just not ethical«
Zwar bietet das Unternehmen selbst auch einen Service an, um Seiten manuell aus dem Semalt-Index zu nehmen, dieses Angebot aber erscheint mir in etwa so verlockend wie der Trichter eines Ameisenlöwen für Insekten.
Jetzt gibt es zwei Möglichkeiten, über die .htaccess mit solchen Gästen umzugehen. Möglichkeit 1: Man lässt sie gar nicht erst rein.
RewriteEngine on
RewriteCond %{HTTP_REFERER} semalt\.com [NC]
RewriteRule .* — [F]
Möglichkeit 2: Man schickt sie postwendend wieder nach Hause (und leitet den Crawler einfach auf die Semalt-Seite »zurück«). Ich finde die zweite Möglichkeit lustiger.
RewriteEngine on
RewriteCond %{HTTP_REFERER} semalt\.com [NC]
RewriteRule (.*) https://www.semalt.com [R=403,L]
Natürlich sieht Semalt das ganz anders. Noch grotesker: Eine auch an anderen Stellen im Netz mehr als umtriebige Mitarbeiterin hält dieses Vorgehen sogar für unethisch (Wobei sich das Unternehmen in der Ethik-Frage am Ende wohl doch nicht ganz sicher war — inzwischen wurde der Tweet wieder gelöscht).
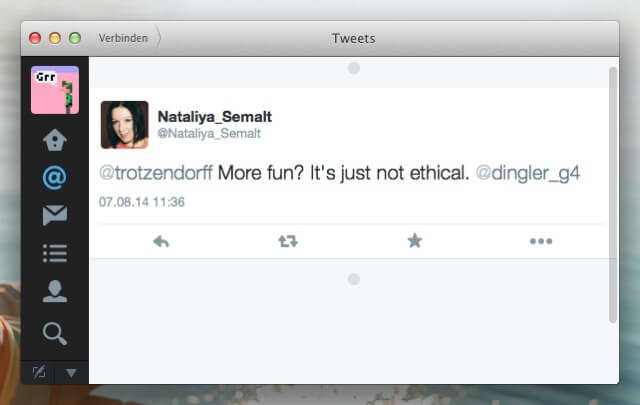
Klingt schwer nach einem Treppenwitz der Netzgeschichte.
P.S.: Es gibt auch zwei GitHub-Projekte, um den Semalt-Crawler zu blocken, eines davon von van den Boezem selbst. Ich habe beide nicht ausprobiert, aber der Vollständigkeit halber sollen sie hier nicht fehlen.
Florian, your accusations are groundless. Semalt has nothing to do with your accusations. We are engaged in a legitimate business, provide a web analytics service for webmasters. If you are interested how Semalt Crawler works, I recommend you to visit our blog and learn more before making conclusions. blog.semalt.com
Anyway, many people, many minds. I’m not gonna argue with you. But it is not professional — spreading misinformation.
To decide if your business is legitimate is a thing for lawyers or judges, I think. And to gather sources is not misinformation, but the opposite. It’s information at its best. And it’s not only professional, it’s my job.
Herzlichen Dank für diese Aufklärung, die stehen bei mir auch täglich drin, auch wenn ich mich noch nicht zu den 2 Minuten aufraffen konnte, die auszusperren…
Freut mich jedenfalls, dass du wieder da bist.
(Und ich nehme mir vor, diesmal mehr zu kommentieren.)
Ha! Und noch einer für die Blogroll … :-)
Danke für die Easy — Erleuchtung, ich wünsche Dir noch viel Erfolg, Schaffenskraft und viele Humane Leser !